

Lo stack tecnologico dell’intelligenza artificiale (AI tech stack) si articola su tre livelli principali:
Livello superiore – Applicazioni: ChatGPT, Gemini, Copilot.
Livello intermedio – Modelli: GPT-5, Llama, Mistral.
Livello di base – Calcolo (Compute): chip, memoria e packaging.
Concentriamoci sul livello fondamentale, il mondo dell’infrastruttura di calcolo.
Produttori di apparecchiature
ASML, Lam Research, Applied Materials.
Queste aziende forniscono gli strumenti e i macchinari essenziali per la produzione di semiconduttori (litografia EUV/DUV, deposizione, incisione). Sono loro a determinare il ritmo dei progressi tecnologici dell’intero settore.
Fonderie (Foundries)
TSMC, GlobalFoundries, UMC, SMIC.
Producono chip per conto terzi. Il loro modello di business si basa sul volume di wafer processati, sulla resa produttiva (yield) e sulle capacità di packaging avanzato.
Società “fabless” (senza impianti produttivi propri)
NVIDIA, AMD, Qualcomm – e, sempre più spesso, le grandi aziende tecnologiche con progetti interni dedicati.
Queste società si concentrano sulla progettazione dei chip e sull’innovazione architetturale e software, affidando la produzione alle fonderie.
Produttori integrati (IDM – Integrated Device Manufacturers)
Intel, Samsung, Micron, Texas Instruments.
Disegnano e producono internamente i propri semiconduttori. Tra questi, Intel è l’unico player con sede negli Stati Uniti che continua a investire su larga scala nella produzione di logiche di ultima generazione.
Fornitori di strumenti di progettazione e proprietà intellettuale (IP)
Arm, Synopsys, Cadence.
Mettono a disposizione set di istruzioni, librerie e strumenti di design indispensabili per la progettazione dei chip e per l’intero ecosistema.
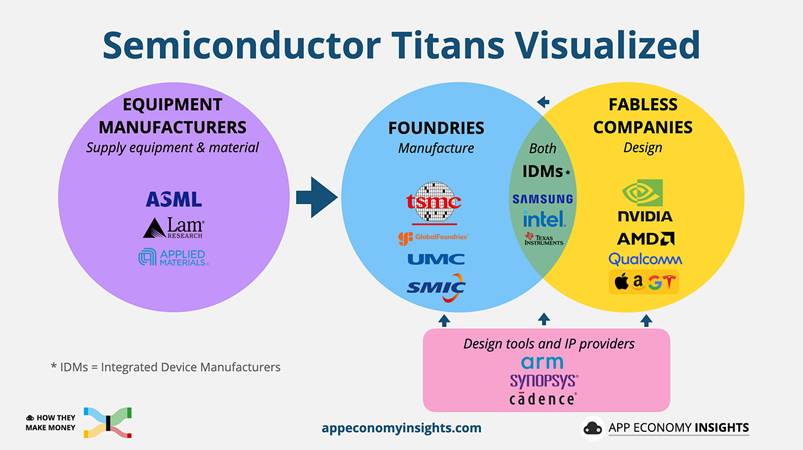
TSMC e Intel
La maggior parte dei chip logici all’avanguardia utilizzati per l’addestramento e l’inferenza dei modelli di AI è prodotta da Taiwan Semiconductor Manufacturing Company (TSMC) – con Samsung che segue a distanza.
Il fatto che tali capacità produttive siano concentrate in un’unica azienda e su un’unica isola rappresenta un rischio strategico per la sicurezza nazionale e la resilienza della catena di approvvigionamento statunitense.
Intel costituisce oggi l’unica via domestica per riportare on-shore la produzione di logiche avanzate e tecniche di packaging su scala significativa; per questo motivo, i decisori politici la considerano un’infrastruttura strategica per la sovranità tecnologica degli Stati Uniti.
Il ruolo di NVDA
NVIDIA ha un ruolo centrale in questo ecosistema e le sue scelte tecnologiche influenzano diverse società.
TSLA — Tesla: guida alla “AI fisica”
Tesla è il principale esempio di applicazione “fisica” dell’AI (veicoli autonomi, robotica, sistemi che fanno percezione e azione nel mondo reale). La visione di Jensen Huang (NVIDIA) sull’“agentic AI” — agenti che agiscono, ragionano e interagiscono con il mondo — è parallela all’obiettivo di Tesla di distribuire AI che muove e controlla sistemi fisici. Questo posiziona Tesla come un leader nell’adozione pratica di concetti che Nvidia sta industrializzando a livello di hardware e piattaforme (simulazione, tool di training e SDK per robotica/automotive).
AVGO — Broadcom: ponte tra compute, memoria e IO
Broadcom fornisce silicon di rete e interconnessione (switch, SmartNICs, interfacce ad alta larghezza di banda) che riducono la latenza e consentono – a livello di rack e di campus di data center – l’integrazione di sistemi GPU complessi. Man mano che NVIDIA enfatizza architetture “full-system” a bassa latenza (GPU + networking + acceleratori), il ruolo di Broadcom come fornitore di switching ad alte prestazioni e di componenti custom diventa critico per abilitare le topologie che NVIDIA richiede. Recenti annunci di Broadcom mostrano il rafforzamento del suo portafoglio networking pensato per AI su larga scala.
ASML: la litografia che rende possibili le roadmap GPU
ASML produce i sistemi EUV indispensabili per i nodi logici più avanzati. Le architetture GPU più dense e performanti (es. la famiglia Blackwell di NVIDIA) dipendono dalla litografia avanzata; senza ASML la fab-capability necessaria per le future generazioni non esisterebbe. In breve, ASML è il fornitore critico che rende fisicamente realizzabili le roadmap dei processori AI
TSM — TSMC: il produttore delle GPU avanzate di NVIDIA
TSMC è il principale costruttore delle GPU NVIDIA di fascia più alta: la combinazione di processo a nodo avanzato, tecniche di packaging (CoWoS, CoWoS-L) e capacità di integrazione HBM è alla base delle prestazioni che NVIDIA commercializza. Le limitazioni di packaging e la capacità wafer/CoWoS definiscono la scala e il costo della produzione Blackwell; perciò la relazione TSMC–NVIDIA è il pilastro economico e tecnologico del dominio NVIDIA nell’AI accelerata.
AMD: l’alternativa di alto livello (competizione e pressione sulla capacità)
AMD offre una proposta concorrente per l’inferenza e l’addestramento (famiglia MI300X) che, in certe metriche (memoria, bandwidth), si pone come valida alternativa. L’esistenza di AMD come competitor riduce la dipendenza del mercato da NVIDIA e può guadagnare rilevanza quando la domanda eccede la capacità produttiva di NVIDIA, creando dinamiche di prezzo e allocazione di capacità tra i fornitori di hyperscaler.
ARM: scala il calcolo a bassa potenza per l’inferenza ai bordi
Arm fornisce le architetture CPU (Neoverse, core per edge) che, combinate con le soluzioni NVIDIA (Drive, Jetson, Grace), permettono inferenza in tempo reale e distribuita. NVIDIA sta spingendo verso architetture ibride (GPU + CPU Arm) per carichi real-time e agentici al bordo; Arm è quindi un pilastro per portare parte del workload AI fuori dal data center verso soluzioni a basso consumo
PLTR — Palantir: orchestrazione e sicurezza per deployment su scala sovrana
Palantir fornisce strumenti di orchestrazione, governance e sicurezza (Gotham/Foundry) necessari per il deployment “sovereign-grade” dei LLM e dell’infrastruttura AI. Per infrastrutture basate su GPU NVIDIA (soprattutto in ambiti regolamentati o governativi), la capacità di Palantir di integrare, monitorare e assicurare l’ecosistema è un elemento abilitante per l’adozione su scala nazionale.
IREN: data center verticalmente integrati e a basso impatto energetico
Società come IREN (operatori di data center progettati per workload AI e alimentati da rinnovabili) trasformano GPU NVIDIA in infrastrutture scalabili e sostenibili: il valore di NVIDIA cresce se è possibile mettere le sue GPU in data center a basso costo energetico e con capacità di scaling rapido. IREN e simili offrono stack colocation / AI cloud ottimizzati per acceleratori NVIDIA.
ANET — Arista Networks: networking rack-scale per GPU
Arista fornisce switching ad alte prestazioni e strumenti di orchestrazione del network necessari per ottenere throughput e latenza adeguati alle topologie GPU-densità. NVIDIA ha ampliato la sua strategia includendo soluzioni di networking a supporto delle GPU (Spectrum-X, SuperNIC); la convergenza fra NVIDIA e fornitori come Arista è fondamentale per sfruttare al meglio cluster di GPU a scala. Recenti migrazioni di alcuni hyperscaler verso stack che integrano soluzioni NVIDIA hanno impatti diretti su Arista.
AMAT — Applied Materials: strumenti per la complessità del packaging e del multi-die
Applied Materials sviluppa macchinari e processi (hybrid bonding, metrologia, deposizione avanzata) che abilitano packaging multi-die, bonding die-to-wafer e altre tecniche necessarie per i sistemi GPU moderni. Con NVIDIA che sposta la roadmap verso design multi-die (es. Blackwell dual-die con CoWoS-L), i fornitori di equipment come AMAT sono essenziali per rendere producibili quelle architetture.
VRT — Vertiv: raffreddamento, alimentazione e continuità operativa
Vertiv progetta sistemi di alimentazione ad alta efficienza, architetture 800-VDC e soluzioni di raffreddamento (liquid/immersion) co-sviluppate con NVIDIA per supportare rack estremamente densi. Mentre NVIDIA spinge verso densità di potenza multiple per rack (per piattaforme come GB200/GB300), la disponibilità di soluzioni Vertiv è imprescindibile per mantenere uptime e prestazioni dei supercluster NVIDIA.
ALAB — Astera Labs: risolve i colli di bottiglia GPU↔memory (PCIe / CXL)
Astera Labs (ALAB) fornisce soluzioni di connettività e retiming (PCIe, CXL, retimers, smart cables) che estendono e stabilizzano collegamenti ad alta velocità tra host, CPU e GPU. Queste tecnologie sono critiche per massimizzare il throughput nei workload di inferenza ad alta memoria che NVIDIA promuove: ridurre la perdita di segnale, estendere il reach di PCIe/CXL e abilitare topologie rack-scale consente a più GPU NVIDIA di operare come un unico dominio coerente.
NVTS — Navitas Semiconductor: conversione e gestione della potenza per l’AI factory
Navitas e simili sviluppano soluzioni di potenza avanzata (GaN/SiC, architetture 800-VDC) che ottimizzano efficienza, densità e scalabilità delle infrastrutture di calcolo. NVIDIA sta promuovendo architetture di “AI factory” a 800 VDC per ridurre conversioni e costi di distribuzione dell’energia: fornitori di conversione/semiconduttori di potenza come Navitas diventano quindi partner tecnologici naturali per rendere sostenibile e scalabile il data-center denso di GPU.
NBIS — Nebius (AI-native cloud): scala infrastrutture GPU-centriche
Provider di AI-native cloud (es. Nebius / NBIS) costruiscono e commercializzano “AI factories” che usano infrastrutture GPU NVIDIA: acquistano cluster H100/H200/Blackwell, orchestrano schedulazione, storage e networking, e offrono capacity elastica ai clienti. La crescita di questi operatori è strettamente legata alla disponibilità di GPU NVIDIA e alle scelte di prodotto di NVIDIA (modelli, form factor, roadmap). I grandi contratti di Nebius per fornire GPU a hyperscaler mostrano come l’ecosistema cloud dipenda strettamente dall’hardware NVIDIA.
NVIDIA non è soltanto un venditore di GPU: è il centro gravitazionale che coordina domanda di packaging avanzato (TSMC, AMAT), capacità di fabbricazione (TSMC), strumenti di litografia (ASML), networking rack-scale (Broadcom, Arista), soluzioni di potenza e raffreddamento (Vertiv, Navitas), connettività ad alta velocità (Astera Labs) e fornitori di servizi/cloud che monetizzano la capacità (Snowflake, Nebius).
Ogni singola società nell’elenco beneficia (o è sfidata) dalle scelte di prodotto, packaging e go-to-market di NVIDIA: quando NVIDIA scala, l’intera supply chain e l’ecosistema di servizi lo fanno con lei.
E intorno a NVIDIA si è creata un’economia circolare, che è riassunta in questa immagine:
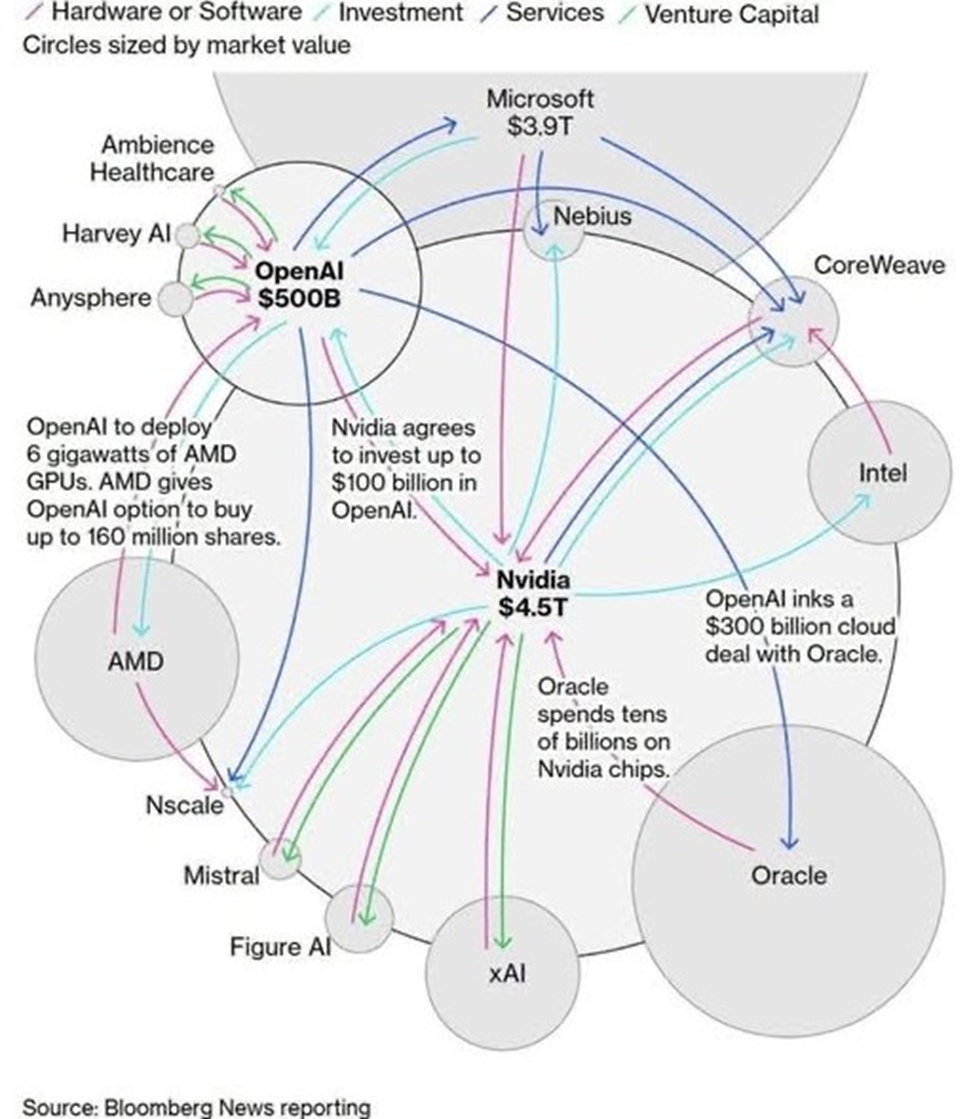
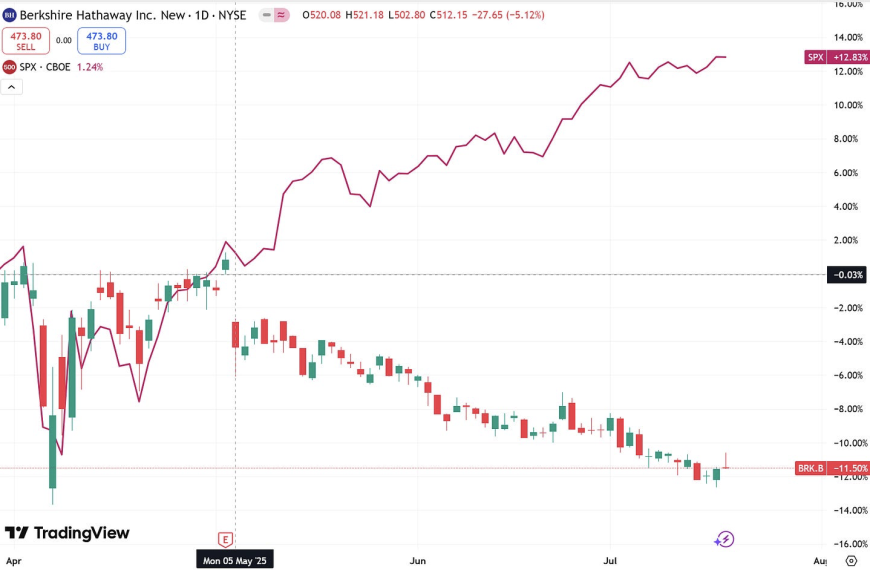
Questo è l’ecosistema delle società che ruotano intorno all’AI, e che solleva qualche più di una preoccupazione qualora una società come NVDIA fosse colpita da nuove restrizioni all’export di chip, o qualora la Cina invadesse Taiwan, compromettendo la capacità produttiva di TSMC (che anche per questa ragione, è stata tra le prima ad accogliere l’invito della presidenza Trump a produrre negli Stati Unti).
Ora capisci perché è dall’inizio dell’anno che ti parlo di Strategie di Copertura (Hedging Strategies ☂️)?
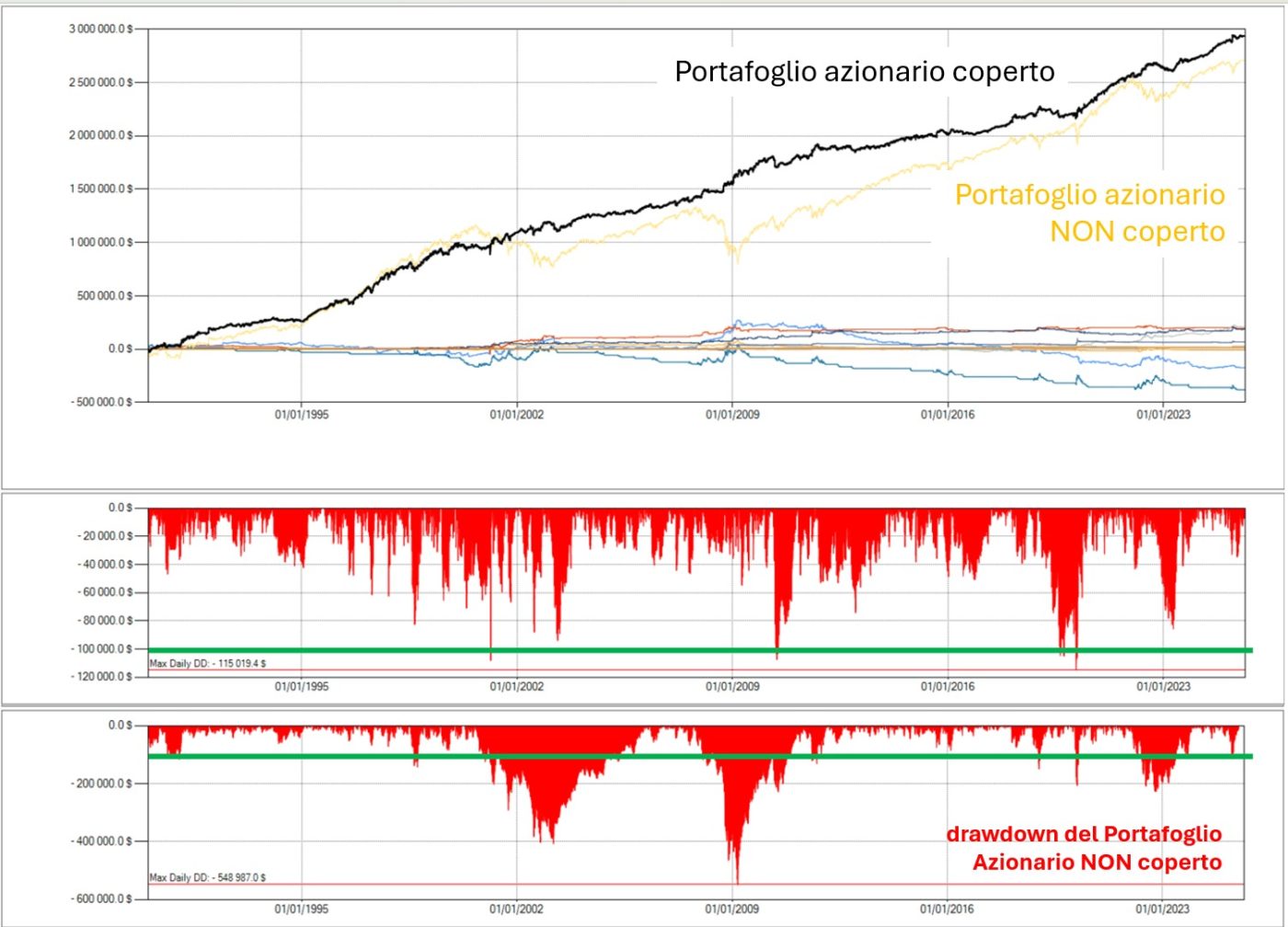
Perché prima o poi qualche nodo verrà al pettine, e se non avrai predisposto delle contromisure per proteggere il tuo portafoglio, non sarà semplice limitare i danni…
Tutto il lavoro che abbiamo fatto sulle Strategie di Copertura è stato sistematizzato nelle 5 giornate di formazione di Hedging Strategies ☂️: le registrazioni e tutto il materiale didattico sono già disponibili, e puoi accedere ad una Community riservata ai partecipanti, dove puoi fare domande e puoi interagire con gli altri allievi.

Qui puoi esaminare il programma dettagliato di questo corso.
Inizia subito a lavorarci sopra, perché mai come oggi è importante non farsi trovare impreparato e agire prima (e non dopo) che il problema si è abbattuto sui mercati.
Luca Giusti





Lascia un commento